Experimental scenario (video)
Source speech
Microphone
Radio2Speech (Ours)
Quiet scenario
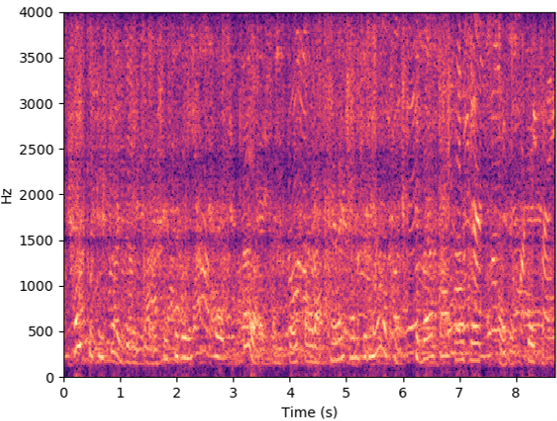
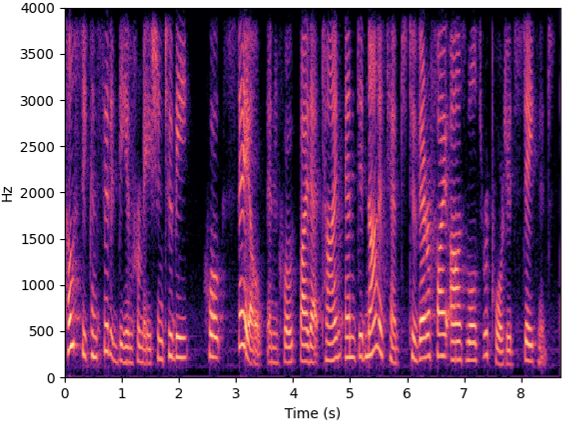
Noisy scenario
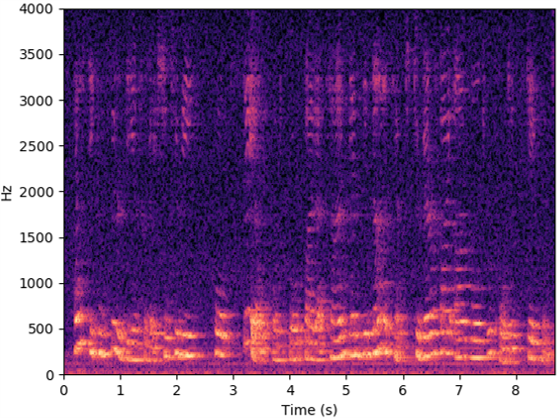
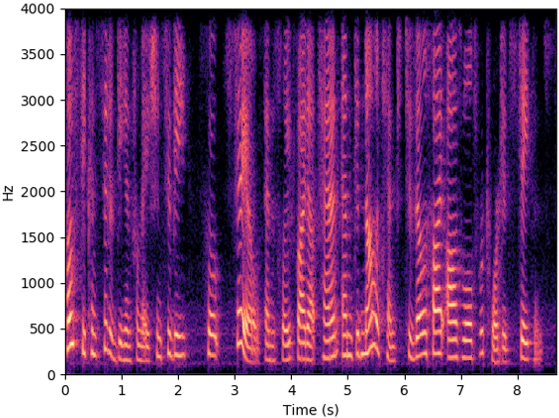
Soundproof scenario
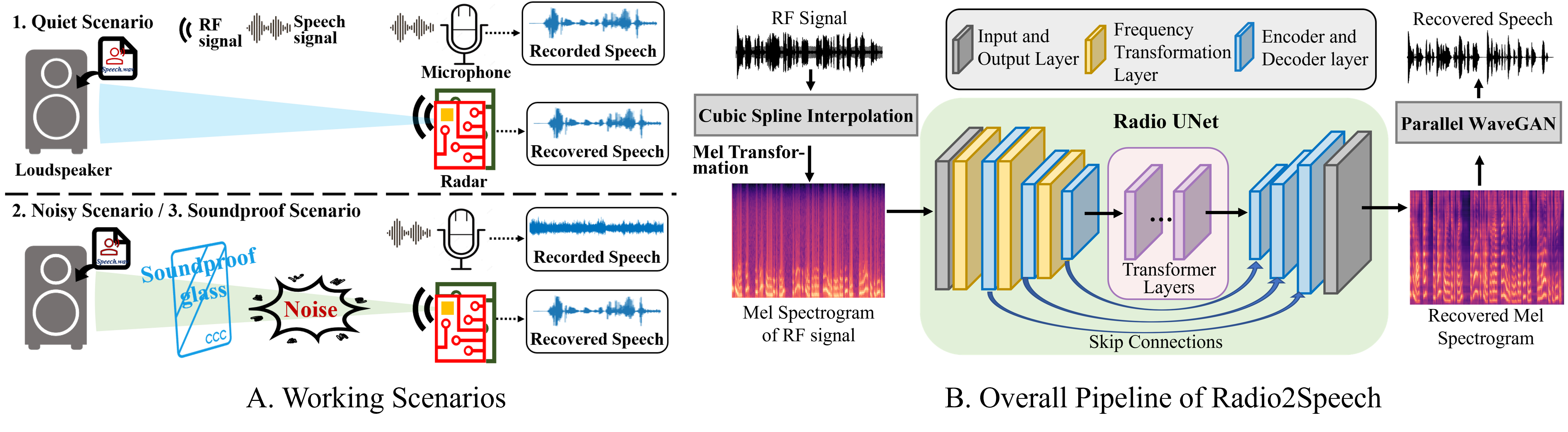
The below videos show the experimental scenarios (i.e., quiet, noisy and soundproof scenarios) of RF data collection, and videos are recorded by a mobile phone. The source speech (8KHz) from LJSpeech (LJ047-0073) are provided for listeners to refer to. Speech examples recorded by the microphone and recovered by Radio2Speech are also show below, and they are recorded in the corresponding scenarios or recovered from the data collected in the corresponding scenarios. Moreover, spectrograms are presented to visualize the recovered speech.
Experimental scenario (video)
Source speech
Microphone
Radio2Speech (Ours)
This section presents the comparison results of speech recovery. Some speech samples recovered from WaveEar and Radio2Speech (ours) and the corresponding speech samples recorded by microphone are provided for readers to better evaluate our system. The source speeches (8KHz) are also provided. We recommend that listeners use headphones for best audio experience. All of the following speech samples were unseen during training, and the results were selected at random. The first five samples are from LJSpeech dataset (i.e., LJ047-0049, LJ047-0128, LJ047-0225, LJ048-0011, LJ048-0083), and the last three samples are from TIMIT dataset (i.e., FAEM0/SX42, MGXP0/SX97, MTWH1/SX72).
(1) Quiet Scenario
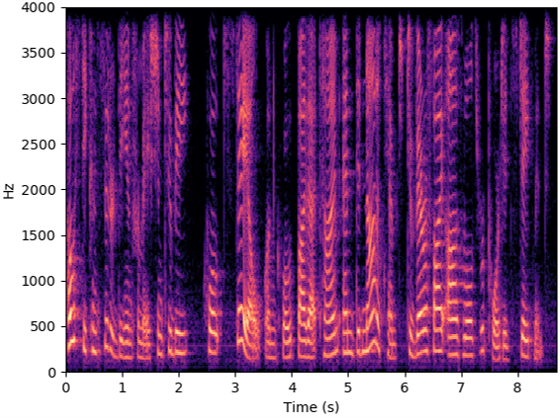
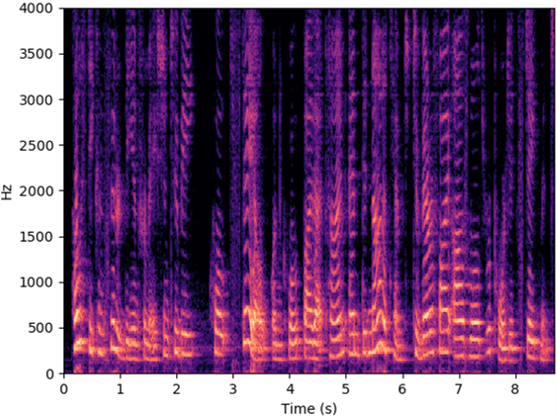
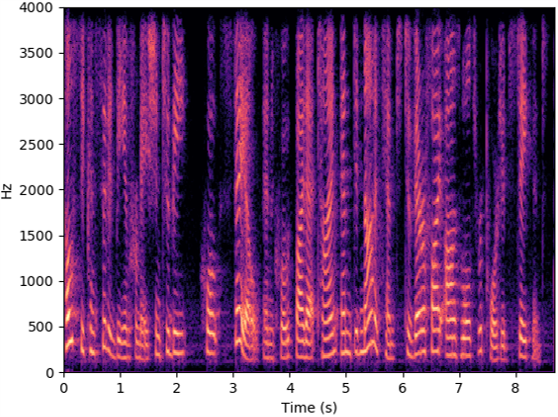
The speech samples in this section are collected in quiet scenario or recovered from the data collected in quiet scenario.
Source speech
Microphone
WaveEar
Radio2Speech (Ours)
(2) Noisy Scenario
The speech samples in this section are collected in noisy scenario or recovered from the data collected in noisy scenario. Since the acoustic noise does not affect RF-based systems, the speech recovered in noisy scenarios is similar to that recovered in quiet scenarios.
Source speech
Microphone
WaveEar
Radio2Speech (Ours)
(3) Soundproof Scenario
The speech samples in this section are collected in noisy scenario or recovered from the data collected in soundproof scenario.
Source speech
Microphone
WaveEar
Radio2Speech (Ours)
Thanks to Despoina Paschalidou for the website template.